Analysis & Data Handling
Custom Analysis & Reporting Capabilities
The platform was designed with extensibility in mind, enabling users to perform tailored analysis routines beyond built-in methods like DTW. This allows for case-specific investigations, on-demand reporting, and integration of new analytical techniques over time.
- Users can trigger different types of analysis by selecting options in the frontend and submitting configuration parameters
- Each analysis module returns structured results (e.g. JSON, DataFrame) that can be rendered or downloaded
- Results are sent to Redis and logged to PostgreSQL for traceability or re-analysis
- Modular backend structure allows future support for external scripts written in R, Bash, or compiled C++
- Supports summary statistics, batch comparisons, and configurable time windows
Time Series Analysis
A core part of this project involved building a system capable of performing computationally intensive operations, with a focus on dynamic and comparative time series analysis. One of the primary techniques implemented was Dynamic Time Warping (DTW), which was developed both as a custom script and using a supporting Python library.
- DTW used to compare process parameters between time ranges or batches
- Includes a traceback method to determine alignment paths through the cost matrix
- Normalisation and min/max scaling applied to enhance comparison accuracy
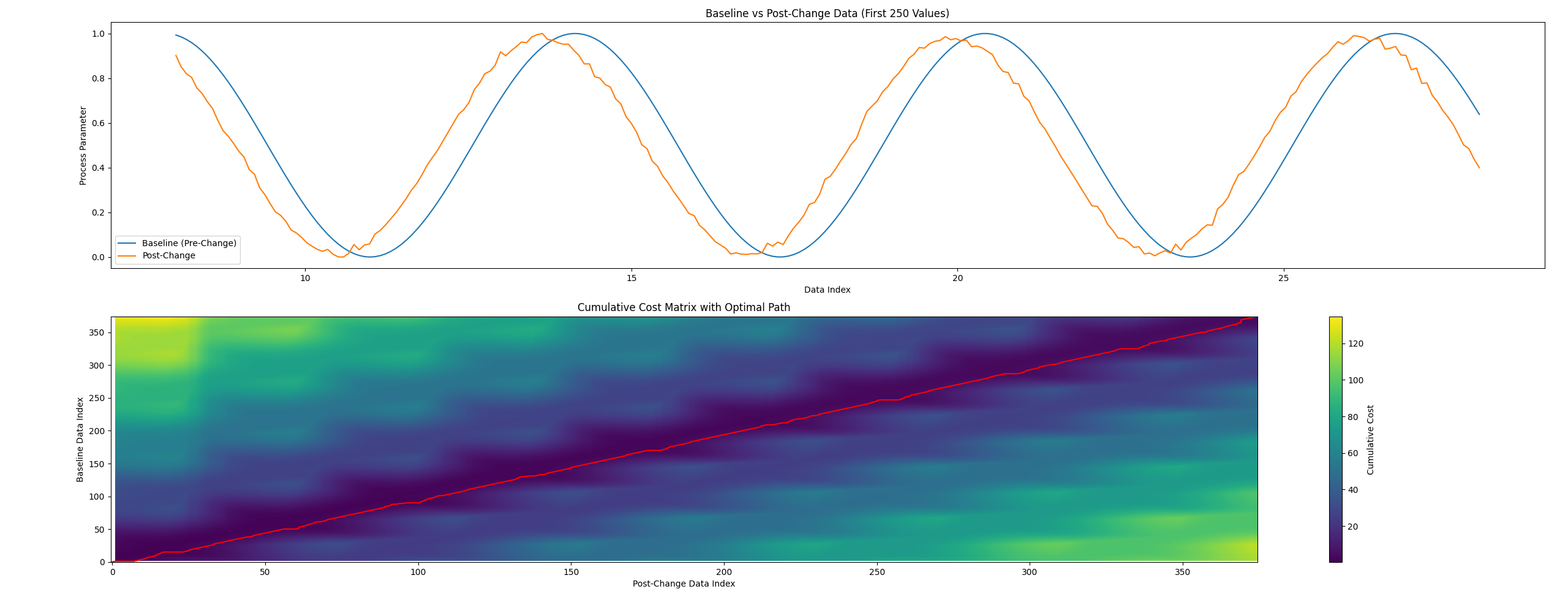
Visual output of DTW analysis showing baseline vs post-change signal (top) and optimal path through the cost matrix (bottom).

Formula showcased in Volume One used to compute each cell of the DTW cost matrix. The path is constructed based on the minimum cost from match, insertion, or deletion operations.
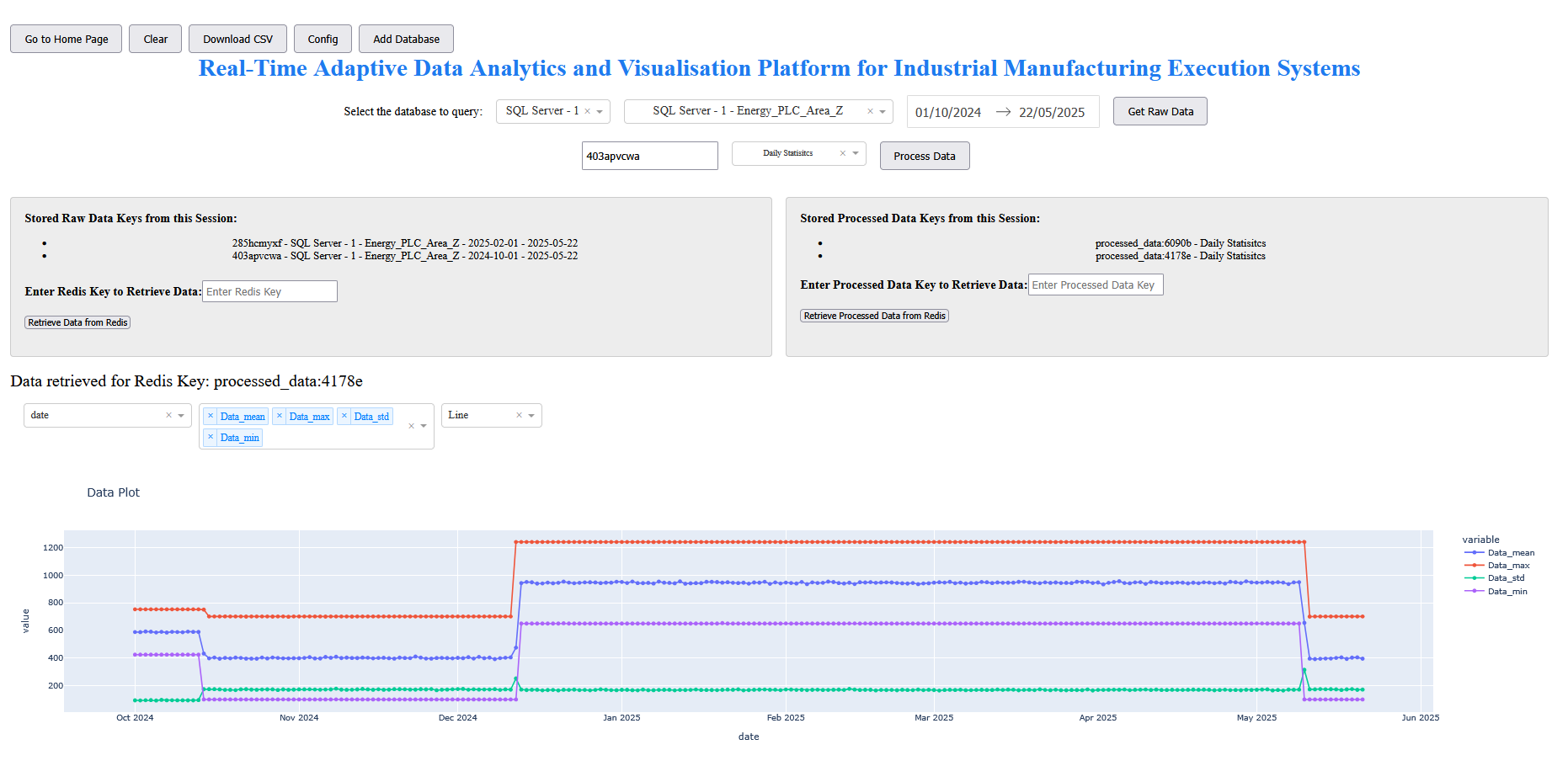
Graphical output of simple anlaysis.
Redis Caching Strategy
Redis was implemented as a high-speed in-memory cache to support both raw and processed data retrieval. This caching significantly reduced load on source databases and sped up repeat analysis operations. The cache can allow for quick access to frequently queried data without hitting the database each time.
- Custom TTL used to retain data as required
- Separate keys tracked for raw queries and results for logging purposes
- Memory monitoring via a Bash script using
redis-cli info memory - Redis Insight used to inspect and debug cache state
Data Dictionary & Preprocessing
A key part of backend analysis was the development of a custom data dictionary framework to classify and prepare incoming data.
- Incoming data parsed into structured
pandasDataFrames - Each column classified as datetime, numeric, categorical, etc.
- Regex logic applied to normalise datetime precision
- Missing data handled using safe defaults and warnings

Custom classification flow used to parse incoming data into structured formats (datetime, numeric, categorical)
This standardised dictionary structure ensures that downstream analysis functions — whether written in Python or other environments such as Bash scripts, C++, or R — can rely on consistent, typed input formats. This design supports long-term modularity and allows the platform to evolve beyond Python-based processing if needed.
Analysis Engine & Modularity
All analysis scripts were designed to accept structured data and return modified DataFrames. This modular approach allows routines to be written in Python now, and later extended in other languages such as Bash or C++.
- Each analysis script imports data, runs a defined function, and returns JSON-ready results
- Statistical methods include rolling averages, range summaries, and time series comparisons
- DTW-based comparisons are triggered by user inputs from the frontend
Error Handling
Robust error handling was implemented across the backend, especially in the abstraction and Redis layers.
- All Redis and HTTP interactions wrapped in
try/exceptblocks - Errors logged with timestamps and status codes
- Custom error messages passed to frontend to inform users
- Validation checks used to prevent malformed queries or missing keys